At DinoCloud, we excel in deploying bespoke solutions supported by AWS Machine Learning. Thanks to AWS, businesses unlock AI’s extensive potential, altering their strategies profoundly. Be it enhancing operational efficiency, refining data security, or fostering innovation, AWS equips companies with avant-garde ML solutions.
Key Takeaways:
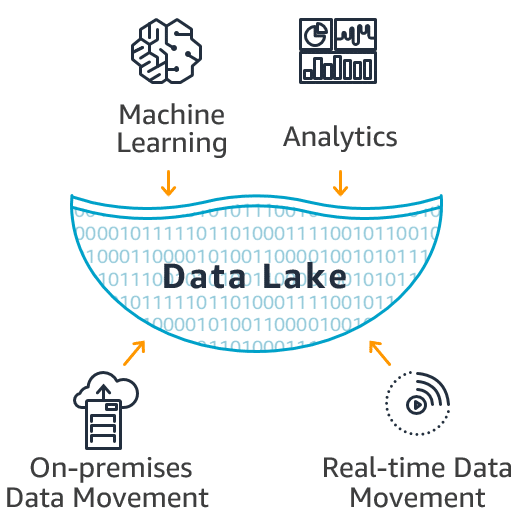
- Majority of industrial facilities struggle with processing vast volumes of unstructured data sourced from sensors, telemetry systems, and equipment dispersed across production lines.
- Standalone foundation models (FMs) face context size constraints, typically handling less than 200,000 tokens, which can be problematic for processing complex industrial data.
- Multi-shot prompting technique betters code generation accuracy, thus enhancing the consistency in creating Python code responses for NLQs.
- Generative FMs are instrumental for asset health assessment, anomaly root cause analysis, and image-based part summaries for equipment diagnosis in industrial applications.
- AWS offers a comprehensive solution architecture for NLQ with time series data, covering ML-driven systems, data translation, NLQ outputs, and Python code creation.
Through AWS Machine Learning, enterprises gain access to advanced AI tools and capabilities. Whether it’s monitoring the health of industrial equipment or creating intelligent text summaries, AWS customizes its offerings to meet diverse needs. By leveraging AI, organizations can lead the way in a world propelled by data.
Exploring AWS Machine Learning Algorithms and Models
AWS is a powerhouse in providing resources for machine learning. It gives businesses a broad selection of algorithms and models to innovate and achieve their objectives. These services from AWS make it quicker to create and use AI solutions, enhancing a company’s AI potential.
Amazon Machine Learning Services and Their Industrial Applications
Amazon SageMaker is a top-notch service within AWS. It offers a playground for constructing, educating, and delivering ML models. SageMaker lets you use advanced algorithms, enhance your data, and easily put your models to work. It is widely used in fields like manufacturing, healthcare, finance, and retail.
Integrating AWS ML Algorithms for Enhanced Operational Efficiency
By picking AWS ML algorithms, companies can introduce new efficiencies. These algorithms power data-led choices and automation, which elevate output and lower expenses. Using AWS ML models gives you tools for predictive insights, spotting anomalies, and more, to refine your processes.
Data Security and Management with AWS ML Solutions
Data safety is paramount when using machine learning. AWS offers strong security features to protect your data. It includes encryption and access controls. Also, AWS helps with managing data, from intake to analysis, simplifying the handling of vast datasets.
AWS Machine Learning: Power and Potential
AWS ML opens the door to AI’s potential for businesses. It helps them increase efficiency, innovate, and choose based on data. With Amazon SageMaker and more, they can speed up their ML projects. AWS ML lets businesses fully use AI and grow in the digital age.
| Amazon ML Service | Key Features |
|---|---|
| Amazon SageMaker | – Pre-built algorithms and tools for accelerated ML development – Data preprocessing and feature engineering capabilities – Easy deployment of ML models to production environments |
| Amazon Polly | – Text-to-speech conversion with lifelike synthesis – Support for multiple languages and accents – Control over pitch, speed, and other aspects of speech |
| Amazon Rekognition | – Highly accurate facial recognition and analysis – Scalable image and video analysis solutions – Easy integration with other AWS services |
| Amazon Lex | – Building voice and text chatbots – Handling both text and speech requests – Deep learning-based conversational capabilities |
| Amazon Comprehend | – Natural language processing capabilities at scale – Text analysis and topic modeling – Insight generation and content automation |
| Amazon Transcribe | – Speech-to-text conversion – Real-time transcription services – Handling low-quality audio and diverse accents |
| Amazon Translate | – Fast and affordable language translation services – Leveraging neural machine translation technology – Support for a broad range of languages |
The Role of AWS SageMaker in Streamlining ML Project Lifecycles
The process of machine learning is a multi-step journey. It starts with preparing data, moves on to training and tuning, and ends with deployment and monitoring. Each of these stages is vital for the successful creation and implementation of machine learning models. AWS SageMaker serves as a robust platform to simplify and enhance the entire ML project cycle. It empowers businesses to efficiently construct, train, and distribute models on a large scale.
SageMaker boasts the SageMaker Data Wrangler, aiding greatly in accelerating and simplifying feature engineering. This step is pivotal in ML endeavors. With Data Wrangler, companies can swiftly preprocess data and undertake feature engineering processes. This operation saves crucial time and effort.
AWS SageMaker includes SageMaker Clarify to identify biases present during data preparation and model training. Detecting and addressing bias ensures the model’s reliability and accuracy. Through Clarify, companies are equipped to evaluate and remediate bias throughout the ML model’s lifecycle. This leads to enhanced model performance and fairness.
The SageMaker Feature Store offers a unique capability for storing engineered features offline. It enables the storage and shared access to standard features, thus improving consistency and reusability. Such feasibility significantly expedites the model crafting process, leading to resource and time savings.
Another key feature of SageMaker is its ML Lineage Tracking module. This tool is crucial for associating every aspect of a model with its development. It facilitates governance and transparency, ensuring adherence to regulatory standards. Organizations can thoroughly trace their model’s history and comprehend its foundation, enhancing regulatory compliance.
SageMaker presents the Model Registry, which centralizes the metadata of components and models. This registry eases the management and surveillance of ML model versions. It offers a structured approach for overseeing model iterations and deployment, simplifying organizational operations.
Moreover, SageMaker Feature Store excels in providing rapid access and processing of new data for model updates. This capability enhances the timely acquisition of real-time data, enabling precise decision-making. It significantly enhances operational efficiency.
Additionally, SageMaker Pipelines offer automation throughout the ML process, mitigating manual errors and enhancing operational speed. This feature substantially speeds up the development and deployment of ML models.
Utilizing AWS SageMaker empowers businesses to leverage advanced tools for efficient ML model creation. It transforms the complex stages of ML workflows into manageable processes. By incorporating SageMaker, enterprises can swiftly evolve and refine their models, fast-tracking ML application into their operations.
In conclusion, AWS SageMaker’s impact on ML lifecycle management is profound. Its suite of tools, including Data Wrangler, Clarify, and others, improves the efficiency and ease of machine learning model development and deployment.
AWS Machine Learning: Unleashing Innovation Across Various Sectors
Cloud-based ML solutions from AWS are changing the game for traditional industries. They empower businesses with AI’s capabilities. This is evident in manufacturing, healthcare, finance, and retail. ML models are key in various tasks like predictive maintenance, personalized healthcare, fraud detection, and demand forecasting.
Thanks to AWS’s ML models and algorithms, companies can boost efficiency and make smart choices from data. This gives them an edge in the competitive marketplace. Companies find it easy to deploy these cloud-based ML solutions. And, they can tweak their models as needed, quickly adapting to market shifts.
In 2017, AWS made a significant mark with the launch of Amazon SageMaker. This service has seen remarkable growth within AWS, boasting over 250 new features to help cut down training times. Now, tasks that once took hours, can be done in minutes.
For cost-effective model deployment, there’s Amazon SageMaker multi-model endpoints and Amazon EC2 compute-optimized instances. These options are great for deploying numerous deep learning models and enabling CPU-based ML inference.
| Industries Leveraging AWS ML | Notable Companies |
|---|---|
| Manufacturing | Siemens, Bayer |
| Healthcare | Philips, AstraZeneca |
| Finance | Capital One, Fannie Mae |
| Retail | Amazon, Mercado Libre |
| Media | Conde Nast, Thomson Reuters |
| Sports | NFL, Formula 1 |
Top organizations are leveraging Amazon SageMaker and other AWS ML tools. They’re discovering new opportunities and transforming their operations. This showcases the wide applicability and success of AWS ML solutions across industries.
Generative AI is also a game-changer, allowing businesses to innovate and stand out. It automates tasks, designs new products, and personalizes experiences. For example, Amazon SageMaker powers Autodesk’s and Torc.ai’s innovations in design and self-driving vehicles. These cases highlight generative AI’s potential in reshaping industries.
By adopting cloud-based ML solutions from AWS, companies are preparing for the future. They are ensuring their relevance and competitiveness in the face of rapid change.
Industries Leveraging AWS ML
| Industry | Notable Companies |
|---|---|
| Manufacturing | Siemens, Bayer |
| Healthcare | Philips, AstraZeneca |
| Finance | Capital One, Fannie Mae |
| Retail | Amazon, Mercado Libre |
| Media | Conde Nast, Thomson Reuters |
| Sports | NFL, Formula 1 |
The Practicalities of Implementing AWS ML into Day-to-Day Operations
Integrating AWS Machine Learning (ML) is key for companies wanting to leverage AI. It unlocks new chances but requires solid planning. In this discussion, we’ll tackle the steps to merge AWS ML with your operations.
To kick off, pinpoint the best use cases for ML in your business. This includes areas like process improvement, better customer service, or data enhancement. Identifying these helps focus your efforts.
Then, it’s time to round up and prep your data. AWS guides you through this, ensuring your data is ready for ML. Remember, the quality and quantity of your data greatly impact your AI success.
Choosing the right ML algorithms for your needs is next. AWS has many algorithms, both ready-made and customizable, to pick from. Test and pick the most effective ones for your objectives.
Training and testing your ML models is critical. AWS ML provides the tools needed. Make sure your models meet accuracy and efficiency requirements against set standards.
After successfully training and testing, it’s about deploying your models. AWS streamlines this step, integrating your AI into daily processes. Ensure your setup is ready to support this phase.
AWS’s documentation and support are invaluable through the process. Make sure to use them, guaranteeing a smooth AWS ML integration. This support aids in every step of your journey to AI.
Understanding your business goals, data needs, and tech capabilities is crucial before starting with AWS ML. Through following best practices and utilizing AWS’s resources, you can effectively use ML. This approach helps you maximize AI in your daily business operations.
Conclusion
At AWS Machine Learning, we empower businesses with technology that unleashes the power of AI. Our platform offers advanced ML algorithms to boost operational efficiency. It allows traditional industries to evolve and ensures future success.
Our cutting-edge tool, AWS SageMaker, simplifies the process of creating and implementing ML models. This streamlining significantly aids businesses in their ML project lifecycle.
Integrating AWS ML into operations requires meticulous planning yet yields remarkable benefits. For scenarios demanding top-notch model diversity, deep ensembles are ideal. Typically, employing around five models ensures high accuracy.
If concerns arise over multiple model hosting or for transfer learning with preexisting models, MC dropout stands as a viable option. Despite possibly longer computational times, iterating data through 30 to 100 times often proves worthwhile.
For settings requiring less predictive variability in transfer learning, MC dropout provides a fitting alternative. It ensures the ensembled models remain closely aligned.
AWS Machine Learning opens doors to AI’s potential, fostering growth and success for businesses. Reach out to us now to explore how we can elevate your operations with AWS ML.
FAQ
What is AWS Machine Learning?
AWS Machine Learning is powered by Amazon Web Services (AWS) in the cloud. It enables businesses to utilize artificial intelligence and machine learning. By doing so, they can find new opportunities and spark innovation.
What are some examples of AWS Machine Learning algorithms and models?
AWS offers a broad selection of machine learning tools. Amazon SageMaker, for instance, delivers pre-built models and innovation tools. Meanwhile, AWS Deep Learning enhances training and model optimization with deep learning capabilities.
How can businesses integrate AWS ML algorithms for enhanced operational efficiency?
Integrating AWS ML algorithms boosts operational efficiency and supports data-driven decision-making. For example, these algorithms aid in predictive maintenance, personalized healthcare, and fraud detection. Such applications make business operations more efficient and effective.
How does AWS SageMaker streamline the ML project lifecycle?
AWS SageMaker acts as a fully managed environment for creating, training, and launching ML models. It streamlines this process by providing pre-built algorithms and simplifying data pre-processing. This allows for quick model iteration and improvement within a business.
How are cloud-based ML solutions revolutionizing traditional industries?
Cloud-based ML solutions from AWS are transforming industries like manufacturing, finance, and healthcare. They introduce AI technologies for predictive maintenance, personalized healthcare, and fraud detection. These changes increase operational efficiency, drive innovation, and adapt to market shifts effectively.