DinoCloud Welcomes Kurt Hopfer as Chief Delivery Architect to Lead North America Growth
DinoCloud announced today that Kurt Hopfer will be joining the company as Chief Delivery Architect leading business development, revenue growth, and operations for North America. His arrival represents a strategic milestone for DinoCloud, enabling us to enhance our offering for clients, gain a deeper understanding of their needs, and deliver services that truly position us as their strategic partner. This step is particularly important as we project significant growth in North America in the coming years.
As a chief technologist, Kurt brings over 20 years of experience guiding companies through cloud adoption and digital transformation. He has successfully led complex migrations and modernization efforts for global organizations in key verticals such as financial services, retail, healthcare, and manufacturing. His primary focus is on translating desired business outcomes into technical solutions leveraging Amazon Web Services (AWS) services and cloud-native technologies. Kurt will be partnering closely with AWS and other strategic partners to drive new opportunities for growth and innovation.
Kurt will be partnering closely with AWS and other strategic partners to drive new opportunities for growth and innovation. At DinoCloud, innovation and growth are part of our DNA, and we are constantly striving to stay in tune with the evolving needs of the market and our clients. With Kurt’s leadership, we are committed to maintaining our position at the forefront of the industry, ensuring that our solutions are always aligned with market demands and continue to deliver exceptional value to our clients.
About DinoCloud
DinoCloud is a leading AWS Premier Partner company in Latin America, formed by teams of professionals with the main objective of accompanying each of its customers to walk the path of learning and implementation of technology trends worldwide. It has success stories in different industries including: healthcare, financial services, transportation and logistics, e-commerce, software as a service and telecommunications, being official partners of the main cloud providers, and one of the most important AWS consulting partners in Latin America.
Team spirit and 360 ° well-being, the four winners tell us how they attract the under 35s.
The leaders of Mercado Libre, DHL Express, DinoCloud, and BEON, the best positioned in the Great Place to Work ranking, told Infobae what their strategies are
The Best Places to Work for Millenials 2021 ranking by Great Place To Work revealed which Argentine companies are distinguished by attracting and retaining young talent.
What distinguishes the companies chosen by millennials?
The best-positioned companies offer 360 ° well-being to their employees. This implies both, a good work environment generated through bonds of respect and care, as well as financial security and job stability.
Great Place to Work, a global people analytics and consulting firm for better business results, interviewed 57,625 employees from 116 participating companies. Among all organizations, 40 achieved a place in the 2021 ranking.
In the 2021 edition of The Best Places to Work for Millennials, the companies that led the ranking were:
– Mercado Libre, in the category of +1000 employees
– DHL Express, in the category of 251 to 1000 employees
– DinoCloud, in the category of 250 to 51 employees
– BEON, in the category of 50 to 10 employees
DinoCloud topped the Best Places to Work for Millennials ranking in the 51-250 employee category.
“At DinoCloud we encourage fellowship and team building activities, we give space to new proposals that may arise, thus creating a relaxed environment to work. Our offices are contemplated and designed so that each one can enjoy relaxation and play spaces, equipped with the comfort they need, in order to find the balance and flexibility between work and personal life, “said Nicolás Sánchez, Chief Operating Officer, in dialogue with Infobae. DinoCloud Officer.
DinoCloud was ranked # 1 in the Best Places to Work for Millennials 2021 ranking in the 51-250 employee category (courtesy DinoCloud / GPTW)
Young talents consider the work environment much more than “just a job”, in that sense Sánchez indicated that “the most valued by our collaborators is culture over other things (with all that this implies) benefits, excellent work environment, fellowship and shared initiatives as a team, without neglecting the opportunity to enhance the professional career. Furthermore, the collaborators give great importance to being able to express themselves freely in their agreements and disagreements, to dialogue and be understood by their leaders ”.
Among the benefits that millennials choose in the world of work, BEON highlighted “a vibrant work culture that combines engagement activities, workshops, virtual and face-to-face games, English classes, recreational outings, and our own comprehensive mental health program, which includes fortnightly therapy sessions ”.
DinoCloud achieves AWS Premier Consulting Partner status.
DinoCloud, a leading adoption of global innovation and cloud computing technologies company, reinforces again its growth trajectory by becoming the new AWS Premier Partner in the region.
This new milestone, which places the company at the highest level within a select global ecosystem, is part of another achievement in its mission to lead the Latin American region, providing high-quality products and services and operational excellence to its customers along with Amazon Web Services (AWS).
“For DinoCloud, reaching Premier level has two dimensions: a confirmation and a starting point. It is a confirmation of the aligned and focused work that the company has been doing since its launch in 2016: certifications and training of talent, success stories achieved in conjunction with AWS, and a company profile capable of making decisions and customer challenges with the highest quality standards, in different regions of the continent.
Moreover, it is a starting point to reaching the next level. Reaching the Premier level consolidates DinoCloud as a world leader in terms of AWS and allows the company and its large commercial investment to achieve better positioning and, therefore, better results. We really consider Premier Level as the bridge between critical customers facing real needs in terms of digital transformation and a company ready and qualified to work together.”
Franco Salonia, CEO at DinoCloud
Partnership at its highest level
Globally, only an exclusive group of companies are part of the highest level of partnership operating under this badge. Obtaining it implies not only having a solid track record as a whole but also complying with a series of rigorous procedures and instances of technical evaluation, demonstration of expertise with relevant success stories, obtaining certifications and competencies, as well as contributing to the development of AWS in the region, with increasingly larger businesses from the technological and commercial standpoints.
Being an AWS Premier Partner is an achievement shared by all organization members and represents the reach of DinoCloud to the rest of the world, which will undoubtedly be accompanied by great challenges and opportunities to continue growing even more.
“Undoubtedly this is the most important achievement since we built DinoCloud. The #1 technology company in the world is certifying and validating us as a global company capable of meeting, under professional services of quality and excellence, the demand that the world generates today. To do so, we need to create and strengthen during these years a unique corporate culture, with a sense of belonging, obsession for our customers, constant technical and professional development, capacity for innovation, and, above all, a team of impressive human and professional quality.
From day one, we thought about this in a big way and today we are just in the first steps, but we have the most important element, which is our team. I am convinced that we can achieve every planned milestone and perhaps much more. Today we strengthen our position as a leader in Latin America in the creation, optimization, and evolution of products deployed in the cloud”.
Lucas Borsatto, CCO at DinoCloud
A long journey traveled
DinoCloud emerged in 2016 with the innovative idea of becoming a 100% customer-focused cloud consulting company that could offer agile solutions in an immature and underexplored market. Faced with a great opportunity, its three founding partners understood that positioning themselves alongside a world-class leader such as AWS Amazon Web Services would lay the foundation for a business model built on the highest quality standards and open the doors to an ecosystem of unlimited opportunities for constant innovation.
With this decisive vision over the last six years, DinoCloud has focused on professionalizing its operational teams under the premise of quality with a 360° technical approach, and on developing commercial support and human resources areas to respond to the growing demand.
In 2020, under a scenario of global uncertainty, DinoCloud was able to find its place and position itself as a key player in the technology market, accompanying a wide variety of companies and institutions from various industries in their technological transformation process toward the cloud, given the immediate need to face new challenges and the emergence of new business models.
In 2021, with a considerable sum of success stories, excellent quality assessments, the acquisition of new technical skills, and exponential growth, DinoCloud managed to strengthen its expansion into the North American market, while receiving a new growth investment with a view to tripling its projections for the coming years. Also, focused on investing in the professional team, the company tripled the number of employees in all areas of the company.
In 2022, DinoCloud is recognized by Great Place To Work as the best company to work for in Argentina, in the category of companies with up to 250 employees, and in turn, achieve the same position in the category Best Places to Work in Technology 2022.
However, the biggest milestone was announced in April, when it was recognized as an AWS Premier Consulting Partner, achieving one of the company’s biggest corporate goals.
“It’s a new achievement, but one of the most important in Dino’s history. For some time now, we have been guiding the team and the brand towards excellence, achieving certifications that endorse the quality of our services and our culture in the highest categories. AWS has inspired our course from the very beginning, and deciding to become a benchmark company not only comes from the fact that we are constantly improving, but also that this great partner gives us the privilege of being part of this elite group of companies that represent the values and quality that make it one of the leading companies in the world.
From the operations perspective, the challenges are ongoing, but we have managed to generate a culture of partnership and joint growth, supported by people who contribute invaluable human qualities in a company that provides professional services. We do not cease to have references, but we are encouraged to invent and implement, often kicking the board and finding maximum efficiency from the very bowels of the organization.
Reaching this point is a consequence of always thinking big, aiming higher, being encouraged, and understanding that mistakes are a sign that we are still trying. In that regard, being Premier is just the beginning of starting to measure ourselves against a new yardstick, and that’s what drives the whole team.”
Nicolás Sánchez, COO at DinoCloud.
About DinoCloud
DinoCloud is a leading AWS Premier Partner company in Latin America, formed by teams of professionals with the main objective of accompanying each of its customers to walk the path of learning and implementation of technology trends worldwide. It has success stories in different industries including: healthcare, financial services, transportation and logistics, e-commerce, software as a service and telecommunications, being official partners of the main cloud providers, and one of the most important AWS consulting partners in Latin America.
Written byFrancisco Semino | Lead Solutions Architect @ DinoCloud
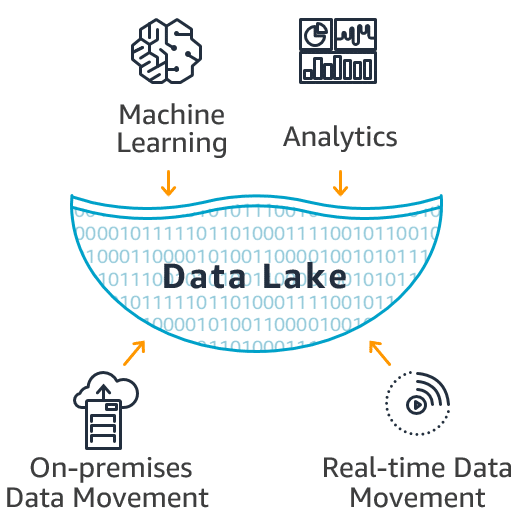
What is a Data Lake?
A company has data distributed in different silos (On-Premise databases), making it difficult to obtain information, gather it, and analyze it to make business decisions. Data Lake provides the ability to centralize all that data in one place. This will allow for processing all the data in the Data Lake and then generating statistics and analysis prior to a business decision. You can create charts, dashboards, and visualizations that show us how the company is, the products, and what the customer wants, among many other options, in addition to the ability to apply Machine Learning to predict this information and make decisions based on it.
A Data Lake is a repository where you can enter structured data (such as from databases) and unstructured (from Twitter, logs, etc.) You can also add images, videos (in real-time or recorded). One of the properties of a Data Lake is that it can be scalable up to Exabyte, a considerable amount of information. It does not imply that it is necessary to have many data to have a Data Lake; it does not have minimums or maximums.
It serves both small and large companies. It is because of its low-cost quality: you pay only for what you use. Being a cloud service, it has the advantage that there is no need to pay for storage “just in case”, but that you pay as you go, according to use. As much as if the Data Lake grows 5GB per month or 5TB per month, it will be paid only for that use.
A little history
What is known as Data Warehouse is the traditional Business Intelligence system of the company, one of its properties is that they only allow structured data. It involves much investment because we would have to pay for capacity (since the Data Warehouse has its processing). That is, this was only used in large companies due to the large amounts of investment required.
The Data Warehouse, due to its high costs and that its clusters are for processing as well as much less capacity than a Data Lake could not be scaled to Exabyte.
Although the most significant difference is that in Data Warehouse, the user defines the schema before loading data, that is, you must know and define what is going to be sent before loading it and then be analyzed by another of the tools of Business Intelligence that will show dashboards, visualizations, etc.
It does not mean that the Data Lake will supplant the Data Warehouse, but rather that it comes to complement it in cases where the company or architecture needs it or already owns it and does not want to get rid of it.
Data Warehouse process for further analysis.
So then, there are three possible architectures:
That the company already has a Data Warehouse and wants to make a Data Lake. Then it can be done in a complementary way, creating a Data Lake separately and all the data from the Data Warehouse, sending it to the Data Lake and using its tools for Big Data processing, Machine Learning, and other issues; otherwise, it could not apply.
The company does not have a Data Warehouse, one is needed, and a Data Lake because the Business Intelligence tool is to be used. The data engineers only support connections to the Data Warehouse where the data is structured. So what is recommended is to raise the Data Lake and create a separate Data Warehouse where all the data ingestion is done through the first one, in order to be then able to send the information directly to the Data Warehouse already transformed, so that the Business Intelligence tool consume it directly from there. In turn, all the data can be used in Big Data processing and all the tools that Data Lake allows us to use.
Finally, and easier: that only one Data Lake is required. A Data Warehouse would not be needed since the Business Intelligence tool directly supports connections to the Data Lake. You could just lift the Data Lake and do all the Business Intelligence and Big Data processing directly from there.
Data Lake Properties
The most important property is that it does not matter where the information is located in an easy, secure way (it travels encrypted) and low cost. Everything can be migrated to a Data Lake: from Premise, from the cloud, from AWS, etc.
In addition to that, other data movements are obtained, which is if the application works real-time, that is, if it is required to send logs of our application, of Twitter tweets to see what the customer thinks of a product and service, it can be done in real-time and thanks to a lot of AWS services.
What is a Data Lake? Source: AWS
Another possibility is that a company has streaming videos in real-time and wants the application to continue to function normally, streaming videos in real-time and storing them in a Data Lake to be analyzed in real-time.
Once the data is ingested, the important part begins: analyze it, take advantage of the Data Lake, make business decisions that affect the company, improve it, improve its product, etc. Then there are two main branches: Analytics on the data, that is, show them on the dashboard, modify them, show visualizations, extract the information.
The second branch: Machine Learning, to be able to predict a little information. There are AWS services that allow analyzing Machine Learning, especially to companies that have experts in this subject, and services that allow small or medium-sized companies not to hire an expert in Machine Learning. For example, AWS Comprehend allows you to understand a bit of natural human language and transform that into ideas: understand what specific tweets are saying, know if they are evaluating it positively, negatively, or neutrally, etc. There are services like Recognition to recognize faces or objects in, for example, a live stream. This is a great advantage today because it allows small and medium-sized companies to have a Data Lake and exploit it without significant investment.
We are often asked in DinoCloud: “how long will my DL be up and running?”. The answer would be no more than two weeks, using what is recommended with essential functions initially, exploiting the data a little, seeing what the company needs, and making dashboards, visualizations, and Machine Learning.
Another common query is: “Would the development of a Data Lake affect my Application / Service that is running in the cloud?”. The answer is simply no. They are entirely complementary questions, in parallel. An application can continue to be developed by performing a Data Lake in parallel without disturbing or the performance being low at those moments in the application. It is because requests are not made directly to the database that the application is using. However, they apply Amazon services that allow extracting all that information from a database-type backup, doing it with the Read Replica, for example, without affecting the application and at a low cost.
AWS SERVICES
S3
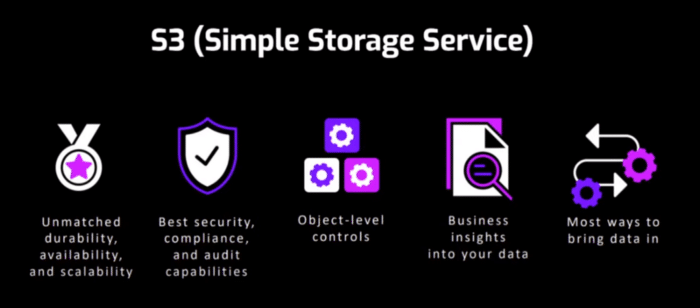
Where do I keep the data, where do I store it, what would my Data Lake be? The answer is Simple Storage Services (S3). It is a storage of objects in Amazon. It is virtually unlimited, meaning that you can load as many exabytes as you need. It has an availability of 99.99%, which allows us to know that all our data will remain safe there, and any disaster or inconvenience that may occur, the data remains backed up. Being Amazon’s first cloud service, it is pretty polished and has much power, a lot to give, and all Amazon services are integrated with S3. This is the most important “why” of choosing S3 as a data storage for a Data Lake. It is also self-scalable, and it only charges for what it is used; it does not pay more.
Another of its main characteristics is security: you can block the permissions to other users, the only ones who can access this data are Amazon services, and you must pass through them to be able to see the data, in addition to being able to encrypt the data. Information through KMS (Key encryption service). You can also control the properties of the object at the object level itself, being able to make it public, for example, a single file within an entire bucket without having to make the entire bucket public.
S3 specific properties.
One of the essential properties of S3 is the number of services that allow you to enter the data as needed. That is to say, it allows to unify of all the dispersed data (in a cloud, on-premise, etc.) in a Data Lake.
In terms of costs, S3 only charges for what is used and no more. These costs are tied to how frequently the user accesses the data that is in S3. S3 Standard has an estimated price of $ 0.0210 per GB.
S3 Standard IA (Infrequently Accessed Data) is next to S3 Standard. For less frequently accessed data, its price is reduced by almost 40%, and it has the same properties as the S3 standard. It is found in 3 availability zones, and it is available all the time; it has milliseconds of access. However, Amazon charges a small percentage of commission per Giga that is extracted, so each time you want to access the data, it will charge a small commission per object that is being requested.
By way of mention, there is also the S3 One Zone IA, which is the same as the S3 Frequently Access with the difference that it is found in an availability zone, with high availability and is generally used for backups. There are also S3 Glacier services, where access to data takes minutes or hours, and S3 Glacier Deep Archive, where there is a delay of 12 to 48 hours to access. These are used for data accessed once or twice a year, and the cost is extremely cheap.
How is the data ingested in a Data Lake? Here are some Amazon services that can be used to enter data:
AWS Direct Connect: allows you to segment and securely send all the data that does not pass through the internet. It is recommended for large amounts of data.
Amazon Kinesis: for streaming data and video
Amazon Storage Gateway: virtual connection between Amazon and an On-Premise. Allows file transfers safely and with all the properties.
Amazon Snowball: commonly used for physical migrations. Scalable up to Terabyte.
AWS Transfer for SFTP: raises SFTP servers and can be used through a VPN.
Kinesis
It is a real-time service from Amazon. It is divided into four sub-services:
Kinesis Video Stream that streams live videos allows that while the stream pipeline is being maintained, the data can be ingested to S3 in real-time or doing analytics on this video.
Amazon Kinesis Data Firehose allows data ingestion in ‘near real time’ to S3, Redshift, etc. If an application is sending events or logs all the time, it allows to ingest the data continuously and in ‘near real time’ to S3, ElasticSearch or Redshift.
Amazon Kinesis Data Stream that allows real-time data streaming but is usually used more to send data to applications, directly to an EC2 to be processed, and is responsible for sending it directly to Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics, real-time analytics that allows you to query the data that is passing live.
4 Kinesis sub-services. Source: AWS.
An essential property of Kinesis is that it is Serverless; you pay only for what you use.
AWS Glue
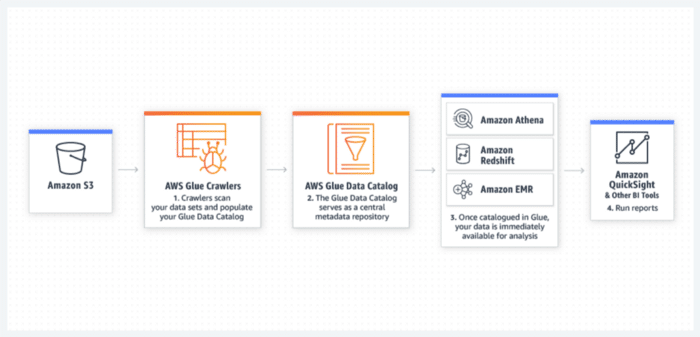
How to consume data from a Data Lake? This answer will begin by talking about AWS Glue. It is an Amazon service with two main parts, Data Catalog, where all the data is cataloged, and all the metadata is obtained and stored there. It allows a Data Lake to be kept organized so that other services can later consume it. It is crucial to have a data catalog. In turn, Amazon Glue has a service called Crawler, which allows the metadata of all the data to be extracted automatically and serverless. A Crawler is created, all metadata is extracted, and you are charged for the minutes it took the Crawler to extract that data. The data store can be S3 or any other storage. This catalog is saved in the Data Catalog part of Amazon Glue, in the form of a database, which shows a table with all the necessary information registered. The formats supported by crawlers are CSV, AVRO, ION, GrokLog, JSON, XML, PARQUET, GLUE PARQUET.
Queries in an Amazon S3 Data Lake
The second part is ETL, significant in the world of Data Lake and Big data, which is the part where all the data is extracted from the Data source, transformed employing a script running in an engine, and then loaded transformed to a target. This does not mean that the Data Source and the Data Target are different, but they can be the same.
Allowed Data Source and Data Target are Amazon S3, RDS, Redshift, and JDBC connections.
AWS Glue Jobs is a service that allows you to run a script on a serverless server. You can add a trigger in this; every time there is a file in S3, a trigger is automatically performed. However, the data must be cataloged to use Job since tables can only be created after being cataloged. For example, if you go from an S3 to a Redshift, the metadata must be present to create Redshift tables. Otherwise, it must be done manually. Then the Job procedure is as follows
extract the data,
perform a trigger in any way (on-demand or by a specific trigger),
extract the data from the source,
run a script that transforms the data, and
return them to carry.
It is essential to know; it is not necessary to know how to program in Python to run the script because Amazon offers the possibility of specifying the transformations that you want to do and writes the script automatically. If a modification is required, the script is available for modification. It is one of the main advantages of Amazon Glue Jobs.
AWS Athena
Another way to consume data from a data lake is AWS Athena. It is an Amazon service that allows me to query the data with SQL queries directly to S3. It is a serverless service. The queries have a performance to process the data at high speed and with fast configuration. Just go to the Amazon Athena console, indicate what data to analyze, and start writing. However, it is necessary to have the data cataloged, or it can be done by hand. You only pay for scanned data. If 1Gb is explored in a query, it will be charged only for 1Gb.
Amazon Athena allows from anywhere, for example, a business intelligence tool that needs to consume data from S3, make the connection, and perform the S3 query. So the Business Intelligence tool where all the dashboards will be displayed has a connection and processing capacity of bringing the data without the need to move all of these to a Data Warehouse.
AWS Elastic Map Reduce
Finally, we will talk about Amazon EMR (Elastic Map Reduce). It is Amazon’s service par excellence in Big Data. It allows to deploy all the applications for all the Open Source frameworks, like Apache Spark, Hadoop, Presto, Hive, and others; it allows you to configure everything in cluster mode. It is self-scalable with high availability. It is vital because there are situations in which a large amount of data needs to be processed at a particular time, so you only charge for that time used, and you save much money. It is a Multi-Availability Zone, and it has data redundancy, and in any situation that happens, everything will remain up and available to the user. It is easy to administer and configure since it does so automatically by going to the console and raising the desired frameworks, indicating the number of nodes required, what types of nodes, and others. Amazon EMR is tightly integrated with Data Lake and all of the services listed above.
After processing all the data and ingesting it, now comes the part that business people are most interested in. The Business Intelligence service is called Amazon QuickSight. It is the first Business Intelligence service that pays per session. In other words, you will only pay each time you enter the QuickSight console, not by users, not by licenses, only by session. There are two types of sessions as in all Business Intelligence: the creator, the user who exploits the data, and the person who views the data to make decisions.
At DinoCloud, we take care of turning a company’s current infrastructure into a modern, scalable, high-performance, and low-cost infrastructure capable of meeting your business objectives. If you want more information, optimize how your company organizes and analyzes data, and reduce costs, you can contact us here.